(fra kap 8 i 'Guds bøddel' av John C. Lennox)
Informasjon i cellen
Vi går nå videre fra proteinnivå til molekylnivå. Her finner vi en av livets grunnleggende byggesteiner: DNA-molekylet. Det var en av allet tiders største vitenskapelige oppdagelser, da dette informasjonsbærende makromolekylet ble kartlagt. En levende celle er spekket med informasjon. Dette vedgår også Richard Dawkins. I følge ham er 'det essensielle i alle livsformer ..informasjon, ord, instruksjoner.. Tenk på en milliard distinkte talltegn.. Hvis en i dag vil forstå livet, må en tenke i IT-baner.' Det informasjonsbærende DNA ligger i cellens kjerne, og gjemmer de instruksjoner nødvendige for å bygge proteinene som en organisme krever, hvis den skal fungere. Selv om DNA er grunnleggende for livet, er ikke DNA 'liv i seg selv'.
DNAet inneholder en informasjonsdatabase og det programmet som skal til for å produsere ett bestemt produkt. Hver eneste av det menneskelige legemes 10 til 100 billioner celler inneholder en database, som rommer mer informasjon enn hele Encyclopedica Brittanica (tidligere største leksikon i verden). Etterhvert som molekylær-biologer ble tvunget til å annerkjenne den genetiske kodens karakter og funksjon, har de tatt til seg av informasjonsteknologiens språk og metodologi. Cellen er en molekylstruktur med kapasitet til informasjonsbearbeiding. Det er en spennende utvikling, fordi den biologiske informasjons beskaffenhet nå kan utforskes ved hjelp av begreper og resultater fra informasjonsteorien.
Hva er DNA?
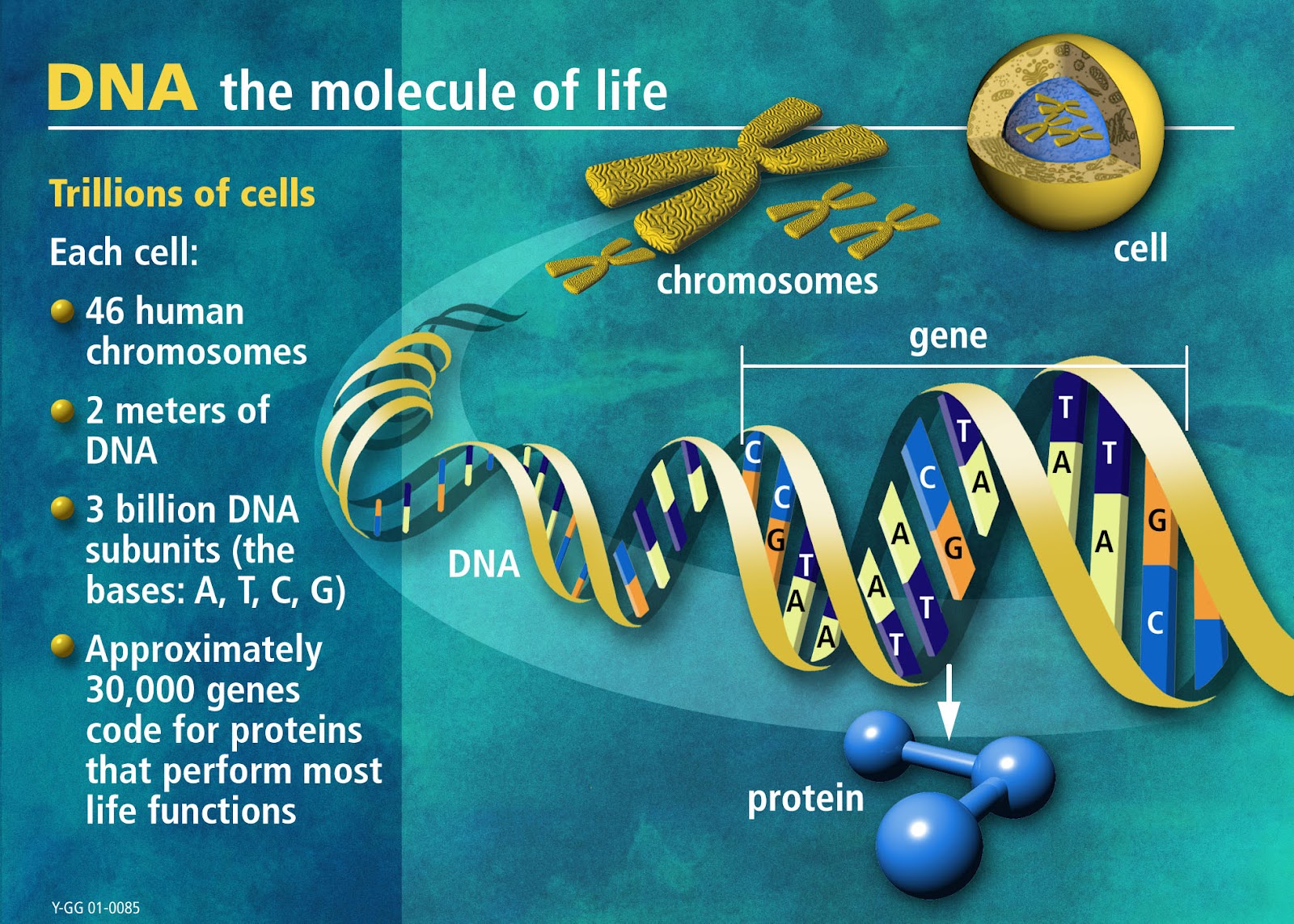 Bokstavene er forkortelse for Deoxyribose Nucleic Acid (Deoxyribose-nukleinsyre) Det er snakk om et meget langt molekyl med en dobbelt-spiralstruktur. Det ligner en vridd taustige og består av en meget lang 'vindeltrapp' av en meget lang kjede av veldig enkle molekyler (nukleotider). Nukleotider består av tre deler: en sukkergruppe (deoxyribose), en fosfatgruppe -som et oksygenatom er fjernet fra (derav -deoxy) og en base. Trappetrinnene i vindeltrappen dannes av fire nitrogenholdige baser: adenin, guanin, cytosin og thymin (eller forkortet: A, G,C og T). Det er de som atskiller det ene nukleotid fra det andre. De to første baser er kjemiske forbindelser som kalles puriner og de andre to pyrimidiner.
Bokstavene er forkortelse for Deoxyribose Nucleic Acid (Deoxyribose-nukleinsyre) Det er snakk om et meget langt molekyl med en dobbelt-spiralstruktur. Det ligner en vridd taustige og består av en meget lang 'vindeltrapp' av en meget lang kjede av veldig enkle molekyler (nukleotider). Nukleotider består av tre deler: en sukkergruppe (deoxyribose), en fosfatgruppe -som et oksygenatom er fjernet fra (derav -deoxy) og en base. Trappetrinnene i vindeltrappen dannes av fire nitrogenholdige baser: adenin, guanin, cytosin og thymin (eller forkortet: A, G,C og T). Det er de som atskiller det ene nukleotid fra det andre. De to første baser er kjemiske forbindelser som kalles puriner og de andre to pyrimidiner.
Hvert trinn på stigen i DNA-spiralen dannes av et basepar, hvor de to basepars molekyler holdes sammen av en hydrogenbinding. Baseparene følger bestemte regler: A kobles alltid med T, og C med G. Et purin knytter seg alltid til et pyrimidin ( se bilde). De to trådene er da komplementære, og om en kjenner den ene, kan en regne ut den andre. Vi skal se hvorfor det er viktig. På samme måte som bokstaver i et skriftspråk kan formidle et budskap, kan basene i DNA-strengen det også. Budskapet er helt avhengig av at basene kommer i en bestemt rekkefølge. Vi kan si at i DNAet benyttes et alfabet bestående av bokstavene: A, C, G og T.
Et gen består av en lang rekke av disse 'bokstavene', og det bærer den informasjon som kreves for å danne et protein. En kan si at et gen er det sett instruksjoner som skal til for å danne proteinet. I praksis virker kodingen slik: Hver gang vi har tre nukleotider danner de et sett vi kaller et kodon. Hvert kodon koder for en aminosyre. Det er 20 ulike aminosyrer i levende menneskeceller. Siden det er tre nukleotider i et kodon, og hver av de kan være av 4 ulike slag: gir det 4*4*4=64 mulige kodoner(tripletter) til rådighet. Opp til 6 ulike kodoner kan da kode for samme aminosyre. Herav navnet den genetiske kode.
Genomet består på sin side av et komplett sett av gener. Det DNAet som koder for genomet, er meget omfangsrike. En E-coli bakterie består av omkring 4 millioner bokstaver -og ville fylt 1000 sider i en bok. Det menneskelige genom er ca 5,5 milliarder bokstaver langt, -og ville fylt et helt bibliotek. Den faktiske lengde av menneskets DNA-atom er i underkant av 2 meter (ca 1,8 m) om en strekker ut den oppkveilede spiral-formen. Når det finnes minst 10 billioner celler i kroppen, kommer en opp i en samlet lengde på informasjonen på ca 20 milliarder km. (Det skulle utgjøre avstanden til sola 133 ganger; Bakgrunnskilde: http://www.space.com/17081-how-far-is-earth-from-the-sun.html).
 Genomet utgjør bare en liten del av DNAet, ca 3%. Av de resterende 97% vet vi nå at mye er ansvarlig for regulering, opprettholdelse og omprogrammering av genetiske sekvenser. I tillegg inneholder de meget mobile segmenter av DNAet. De har fått navnet transposoner, fordi de kan framstille kopier av seg selv, og deretter flytte rundt til ulike steder på genomet. Det kan slukke eller aktivere visse gener. Dessuten benyttes ikke-kodende DNA til DNA-profiler i rettsmedisin. Her har hvert menneske en unik profil.
Genomet utgjør bare en liten del av DNAet, ca 3%. Av de resterende 97% vet vi nå at mye er ansvarlig for regulering, opprettholdelse og omprogrammering av genetiske sekvenser. I tillegg inneholder de meget mobile segmenter av DNAet. De har fått navnet transposoner, fordi de kan framstille kopier av seg selv, og deretter flytte rundt til ulike steder på genomet. Det kan slukke eller aktivere visse gener. Dessuten benyttes ikke-kodende DNA til DNA-profiler i rettsmedisin. Her har hvert menneske en unik profil.
Proteiner fra DNA
 DNAet ligger i cellens indre kjerne, beskyttet av en kjernemembran. Før cellen kan produsere noe, må den informasjon som ligger i DNAet transporteres ut i cytoplasmaet utenfor kjernen i cellen, 'fabrikkbygningen', om en vil. Dette skjer i såkalte ribosomer, som kan fremstille enzymer til prosesser i cellen. DNA-informasjon fraktes via m-(messenger)RNA. RNA har en hydroksylgruppe mer enn DNA, men mangler deres dobbelt-strengede form. Dessuten erstattes basen T (Tyamin) med basen U (uracil). m-(messenger)RNA kan sammenlignes med et magnetbånd til en mainframe-computer. Ribosomet kan sammenlignes med en maskin som konstruerer et protein 'i tråd med' instruksen på båndet.
DNAet ligger i cellens indre kjerne, beskyttet av en kjernemembran. Før cellen kan produsere noe, må den informasjon som ligger i DNAet transporteres ut i cytoplasmaet utenfor kjernen i cellen, 'fabrikkbygningen', om en vil. Dette skjer i såkalte ribosomer, som kan fremstille enzymer til prosesser i cellen. DNA-informasjon fraktes via m-(messenger)RNA. RNA har en hydroksylgruppe mer enn DNA, men mangler deres dobbelt-strengede form. Dessuten erstattes basen T (Tyamin) med basen U (uracil). m-(messenger)RNA kan sammenlignes med et magnetbånd til en mainframe-computer. Ribosomet kan sammenlignes med en maskin som konstruerer et protein 'i tråd med' instruksen på båndet.
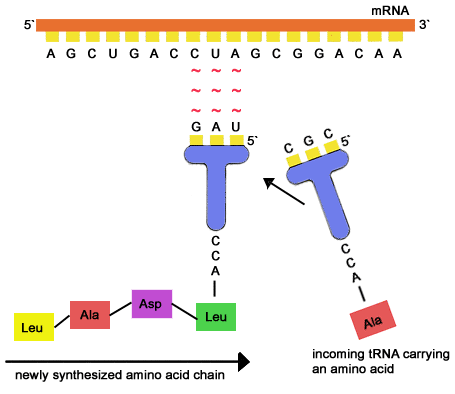
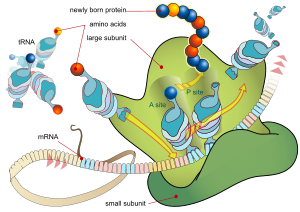
Produksjonen krever at ribosomet beveger seg langs mRNA-strengen for å lese informasjonen innfeldt der. Det er som et magnethode til en båndopptager eller scannings-hode til en Touringmaskin. Kodonet blir avlest på computervis, f.eks: AAC UGC UUG... Oppgaven til ribosomet er så å finne den aminosyren som svarer til kodonene. De aktuelle aminosyrene svømmer rundt i nærheten, og er hektet på molekyler ved ester-bindinger. Disse korslignende molekylene kalles tRNA (transporter RNA) Aminosyren vil være knyttet til foten av molekylet, mens på toppen er et anti-kodon til dette (f.eks UUG som er antikodon for AAC). Ribosomet leser et kodon, søker etter og finner tilsvarende anti-kodon, innfanger det og fjerner aminosyren knyttet til den. Denne aminosyren skjøtes av ribosomet sammen med de foregående, og slik oppbygges gradvis et nytt protein. Dette skjer i en høy hastighet, så godt som uten feil.
Disse bittesmå mekanismene er så små at de må sees gjennom et 'atomært kraftmikroskop (AFM). Vi står her overfor en forbløffende raffinert orden, som et kort blikk i enhver lærebok i molekylærbiologi vil bekrefte. Kompleksiteten er av en slik art at selv ovebeviste neodarwinistiske biologer (eks. John M. Smith og Eörs Szathmary må innråmme at det eksisterende oversettelsemaskineri på en gang er så essensielt, så innviklet og så universelt at det vanskelig å se hvordan det er kommet til, eller hvordan livet kunne ha eksistert uten det. Nesten ti år senere beklager mikrobiologen Carl Woese seg over at selv mennesker med all sin intelligigens, ikke kan konstruere slike mekanismer..
 Selv om DNA er opphav til proteiner, kan ikke replikering av DNA igangsettes uten at det finnes en rekke proteiner. Som en følge av dette har mange kjemikere gått vekk fra RNA-først hypotesen.. Likevel finnes en gruppe som holder på hypotesen om det selvkopierende molekyl. For at den skal stemme, må de da forutsette en 'pre-RNA-verden'. Dette finnes det ikke holdepunkter for, og det virker bare som en forskyver problemet med å forklare livets tilblivelse.
Selv om DNA er opphav til proteiner, kan ikke replikering av DNA igangsettes uten at det finnes en rekke proteiner. Som en følge av dette har mange kjemikere gått vekk fra RNA-først hypotesen.. Likevel finnes en gruppe som holder på hypotesen om det selvkopierende molekyl. For at den skal stemme, må de da forutsette en 'pre-RNA-verden'. Dette finnes det ikke holdepunkter for, og det virker bare som en forskyver problemet med å forklare livets tilblivelse.
Men, om slike replikatorer skulle oppstå tilfeldig -uten bistand fra en kjemiker, ville de støte på problemer av en helt urimelig størrelsesorden. Om det skulle ha funnes en slags 'ursuppe' som på mystisk vis er satt sammen under forhold som begunstiger sammensetning av kjeder av aminosyrer. Da ville nødvendige aminosyrer for oppbygging av liv bli ledsaget av horder av 'defekte byggesteiner' (aminosyrer som ikke kan tjene sluttresultatet). Og hvis de inngår i prosessen, ville de spolere kjedens mulighet til å fungere som replikator. De ville derimot lett fungere som en terminator, en stoppkode, for hele oversettelsesprosessen.
Det er ingen grunn til at ikke en indifferent natur ville sette sammen ulike enheter helt tilfeldig, og dermed framstille en enorm vifte av sammenblandede kort. Vi har tidligere beregnet sannsynligheter for dette, og vil nå i stedet bruke en mye anvendt analogi. La oss forestille oss en svær gorilla ved et enormt tastatur. Tastaturet inneholder språktegn fra alle kjente språk, slik det gjør i en PC. Sjansene for en spontan samling til en replikator alle mulige aminosyrer, kan sammenlignes med at gorillaen skriver en sammenhengende oppskrift på Chili Con Carne. Ut fra lignende overveielser har f.eks. Leslie Orgel fra Salk Institute og Gerald F. Joyce fra Scripps Research Institute konkludert at en spontan fremkomst av RNA-kjeder på den livløse jord, ville ha vært noe av et under.' Schapiro uttaler: 'Man er nødt til å se bort fra at DNA, RNA, proteiner og andre utarbeidede store molekyler når vi taler om livets opprinnelse. Hans alternative 'stoffskifte først' teori, er heller ikke realistisk. Det finnes ikke enighet om hvorvidt stoffskiftet kunne utvikle seg uavhengig av genetisk materiale. Omtalte Leslie Orgel skriver: 'det er intet i den kjente kjemi som rettferdiggjør troen på at lange sekvenser av reaksjoner kan organisere seg selv spontant.. Det er all mulig grunn til å tro at de ikke kan det.'
'Enkle livsformer' -hvor enkle er de?
(fra brosjyren 'Livets opprinnelse')
 Det er i hovedsak to ulike celletyper hos levende organismer: bakterieceller uten kjerne (prokaryote) og plante, dyr- og menneske-celler, med kjerne (eukaryote).Mange forskere mener at eukaryote celler utviklet seg fra prokaryote, ved f.eks. at baktericeller slukte andre celler -uten å fordøye dem.. Om evolusjonsteorien stemmer, burde det være mulig å stille opp en rimelig sannsynlig forklaring på hvordan de første eukaryote celler ble til. Om livet derimot er designet, burde det være mulig å finne tegn på en 'mindful design', selv i de minste detaljene. Vi skal kikke litt nærmere på en prokaryot celle:
Det er i hovedsak to ulike celletyper hos levende organismer: bakterieceller uten kjerne (prokaryote) og plante, dyr- og menneske-celler, med kjerne (eukaryote).Mange forskere mener at eukaryote celler utviklet seg fra prokaryote, ved f.eks. at baktericeller slukte andre celler -uten å fordøye dem.. Om evolusjonsteorien stemmer, burde det være mulig å stille opp en rimelig sannsynlig forklaring på hvordan de første eukaryote celler ble til. Om livet derimot er designet, burde det være mulig å finne tegn på en 'mindful design', selv i de minste detaljene. Vi skal kikke litt nærmere på en prokaryot celle:
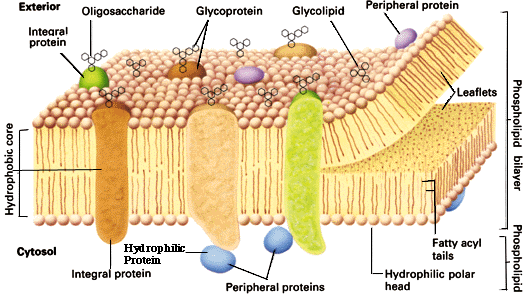
For å anslå størrelsen, så er den flere hundre ganger mindre enn ett punktum. Membranen omkring cella er så tynn at det ville gå 10.000 av den oppå hverandre, for å få tykkelsen til et papirark. Noe av det mest intrikate ved cellemembraner at de har åpninger som kontrolleres av avanserte overvåkningssystemer. Det er 'dørvoktere' som passer på at kun stoffer cellen trenger, slipper inn og at ingen stoff som den trenger -slipper ut. De kan sammenlignes med kaianlegg, som er spesialdesignet til å motta en bestemt type varer.
Cellemembran
 Cellene bruker mye tid og energi til å produsere proteiner. Det gjør den ved å produsere byggeklosser (aminosyrer) som leveres til ribosomer (5). Disse kan sammenlignes med automatiserte roboter (maskiner) som skjøter aminosyrer sammen i nøyaktig riktig rekkefølge til det proteinet som skal dannes. Liksom operasjoner i en fabrikk kan styres av dataprogram (eks. CAD/CAM) så styres funksjonene i en celle ved DNA-koden (6). Ribosomene får en DNA-kopi og har detaljerte instrukser for hvordan den skal bygge spesifikke proteiner. (7) Hvert protein folder seg sammen i en unik tredimensjonal form (8). Hvis ikke proteinet er foldet på eksakt riktig vis, vil det ikke fungere ordentlig og kan skade cellen. Hvert protein får en innebygd adresselapp, som sikrer at proteinet blir levert dit det skal. De kommer fram til nøyaktig rett sted, til tross for masseproduksjon i ribosomene.
Cellene bruker mye tid og energi til å produsere proteiner. Det gjør den ved å produsere byggeklosser (aminosyrer) som leveres til ribosomer (5). Disse kan sammenlignes med automatiserte roboter (maskiner) som skjøter aminosyrer sammen i nøyaktig riktig rekkefølge til det proteinet som skal dannes. Liksom operasjoner i en fabrikk kan styres av dataprogram (eks. CAD/CAM) så styres funksjonene i en celle ved DNA-koden (6). Ribosomene får en DNA-kopi og har detaljerte instrukser for hvordan den skal bygge spesifikke proteiner. (7) Hvert protein folder seg sammen i en unik tredimensjonal form (8). Hvis ikke proteinet er foldet på eksakt riktig vis, vil det ikke fungere ordentlig og kan skade cellen. Hvert protein får en innebygd adresselapp, som sikrer at proteinet blir levert dit det skal. De kommer fram til nøyaktig rett sted, til tross for masseproduksjon i ribosomene.
Bilde. Gjensidig avhengighet -hva kom først?
Komplekse molekyler brytes ned utenfor cellen, og inni cellen trenger de hjelp fra andre komplekse molekyler, selv i den enkleste livsform. F.eks. trengs det enzymer for at det kan dannes energimolekyler (ATP- adenosintrifosfat), og det trengs energi fra ATP for at det skal dannes enzymer. Det trengs også DNA for at det skal dannes enzymer, men også enzymer for at det skal dannes DNA. Også andre proteiner kan bare dannes av en celle, men en celle kan bare dannes ved hjelp av proteiner. Noen av cellene i mennekekroppen består av omkring 10 milliarder proteinmolekyler (11) av flere hundre tusen uolke typer (12).
 Mikrobiologen R. Popa måtte medgi, selv om han ikke tror på Gud, at "de mekanismene som må til for at en levende celle skal fungere, er så komplekse at det virker umulig at de har oppstått samtidig ved en tilfeldighet." (14) Dessto mer forskerne finner ut om hvor komplisert livet er, dessto mindre sannsynlig virker det at det er blitt til ved tilfeldigheter. Noen prøver å skille mellom evolusjonsteorien og selve opprinnelsen til livet. Men mange bygger på oppfatningen at det første livet oppsto som følge av en lang rekke tilfeldigheter. Og den går videre ut fra at en lang rekke ikke-styrte hendelser dannet det rike og kompliserte livet vi finner i verden i dag. Vi kan konkludere med at ingen celle er 'enkel' i den forstand at DNA og kodede instruksjoner er noen enkel materie.
Mikrobiologen R. Popa måtte medgi, selv om han ikke tror på Gud, at "de mekanismene som må til for at en levende celle skal fungere, er så komplekse at det virker umulig at de har oppstått samtidig ved en tilfeldighet." (14) Dessto mer forskerne finner ut om hvor komplisert livet er, dessto mindre sannsynlig virker det at det er blitt til ved tilfeldigheter. Noen prøver å skille mellom evolusjonsteorien og selve opprinnelsen til livet. Men mange bygger på oppfatningen at det første livet oppsto som følge av en lang rekke tilfeldigheter. Og den går videre ut fra at en lang rekke ikke-styrte hendelser dannet det rike og kompliserte livet vi finner i verden i dag. Vi kan konkludere med at ingen celle er 'enkel' i den forstand at DNA og kodede instruksjoner er noen enkel materie.
Bilde. Proteinsyntese i ribosom
Menneskekroppen derimot er av de mest komplekse strukturer i universet. Avhengig av størrelse består den av anslagsvis 100 billioner ørsmå celler, som det går 100 av på 1 m.m. Den har over 200 ulike celletyper, eks. blodceller, nerveceller, muskelceller, benceller, øyeceller og hjerneceller m.m.m. Selv om de ulike nervetypene er meget ulike i form, fasong og funksjon, så er de tett integrert i et superraskt integrert nettverk. Nåværende hastigheter på Internett er trege og nettet ineffektivt i sammenligning.
 Ligger alt i genene?
Ligger alt i genene?
(forts. fra kap 8 i 'Guds bøddel' av John C. Lennox)
Alt snakk om kompleksitet i informasjonsrike bio-molekyler, kan etterlate inntrykk av at genene sier alt om hva det vil si å være menneske. Det har vært holdt som et sentralt dogme blant molekylærbiologer at genomet helt og holdent gjør rede for en organismes nedarvede egenskaper. Det har bidratt til en form for bio-determinisme, som gir uttrykk for at de enkelte gener har ansvar for alt fra sykdommer til matematiske egenskaper.
 Et hierarki av kompleksitet
Et hierarki av kompleksitet
Nå er det imidlertid voksende bevis for at denne bio-determinismen er usannsynlig: Det menneskelige genom viser seg ha færre enn 30.000 gener. Dette er overraskende, tatt i betraktning at menneskets cellemaskiner produserer ca. 100.000 ulike proteiner. Dermed kunne en tro det ville eksistere tilsvarende antall gener til å kode for dem. Det kan virke som det 'er for få gener til å gjøre rede for den utrolige kompleksitet som våre nedarvede egenskaper utgjør.
Når noen vil fortelle oss at genene forteller oss hvem vi er, har de ikke fått tak i hele virkeligheten. Det er altså ikke 'én til én' sammenheng, men 'en til mange' sammenheng mellom gener og proteiner.
Bare et slikt forhold som at genene kan slås av eller på, vil innebære utrolig mange 'uttrykksstadier'. En organisme med n gener, som hver enkelt kan befinne seg i stadiene 'uttrykt' eller 'ikke-uttrykt'. Da er det altså (2 opphøyd i n) ulike uttrykksstadier. OM nå to organismer A og B har h.h.vis 30.000 og 32.000 gener. Ja, så ville det være (2 opphøyd i 2000) ulike uttrykksstadier. En relativt liten forskjell i antall gener, vil i så fall kunne forklare den store forskjellen i fenotyper -(de observerbare 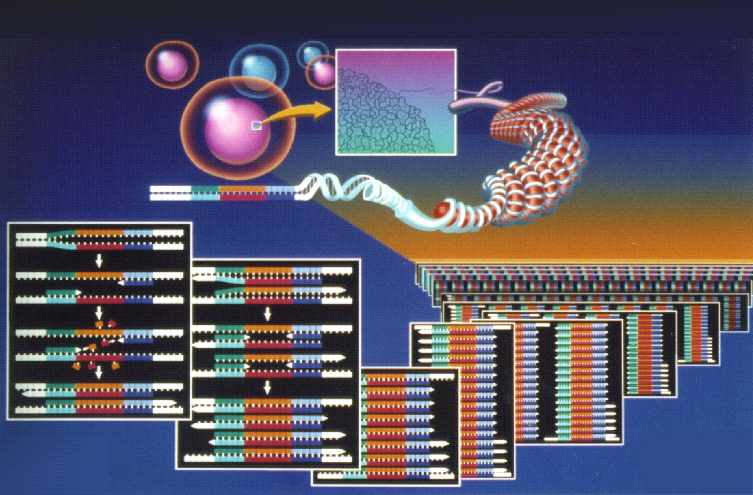 karakteristika). Men i mer komplekse organismer, fins det en langt større vifte av molekylære maskiner de kan bygge opp og kontrollere. For eksempel kan genene være 'delvis uttrykt', som innebærer at de verken er helt tent eller helt 'avslått'. Disse kontrollmekanismene er i stand til å reagere på cellens aktuelle miljø, så miljøet bestemmer i hvilken grad et gen skal være tent eller slukket. Da kan en oppjustere kraftig antall ulike uttrykksformer som kan forekomme. Effekten av proteiner som bearbeider proteiner, gjør at en beveger seg opp i et hierarki av kraftig stigende kompleksitet. Endog de laveste nivåer er vanskelige å forstå.
karakteristika). Men i mer komplekse organismer, fins det en langt større vifte av molekylære maskiner de kan bygge opp og kontrollere. For eksempel kan genene være 'delvis uttrykt', som innebærer at de verken er helt tent eller helt 'avslått'. Disse kontrollmekanismene er i stand til å reagere på cellens aktuelle miljø, så miljøet bestemmer i hvilken grad et gen skal være tent eller slukket. Da kan en oppjustere kraftig antall ulike uttrykksformer som kan forekomme. Effekten av proteiner som bearbeider proteiner, gjør at en beveger seg opp i et hierarki av kraftig stigende kompleksitet. Endog de laveste nivåer er vanskelige å forstå.
Hvor kommer instruksene fra?
Mange biologer og andre vitenskapsfolk mener at DNA-molekyler og kodingen som finnes i dem ble til på tilfeldig vis gjennom millioner av år, uten noen ekstern instans. Hvis evolusjonsteorien stemmer, burde sannsynligheten for at DNA ble til uten noen form for intelligent styring i det minste virke rimelig. Om en går inn og undersøker strukturen hos kromosomer og kveiling av dem i pakkesystemet de opptrer i, så kalles dette pakkesystemet ingeniørkunst av høyeste klasse. (18). Om et tilsvarende varesystem var ordnet så greit at en lett kunne finne en hvilken som helst vare, så ville gjerne tenke at det var velplanlagt og ordnende instans bak det hele. I læreboka Molecular biology of the Cell blir lagring av DNA i cellens kjerne, sammenlignet med å stappe 40 km. svært tynn tråd inn i en tennisball, slik at hver del av tråden var lett tilgjengelig.
Det menneskelige genom består av ialt ca. 3,2 milliarder basepar -eller trinn på DNA-stigen.(19). Om vi tenker på leksikon på ca. 1000 sider hver, så bille informasjonen i det menneskelige genom fylle ca. 855 bind. Å få trykket så mye informasjon inn i hver av de ca. 100 billioner celler vi har, ligger ikke i menneskelig makt. Et gram DNA -ca 1. cm3 i tørr tilstand, kan lagre like mye informasjon som 1 billion CDer. (20) Det finnes ikke noe menneskelig datalagringsmedium som har tilnærmet DNA sin kapasitet. DNA inneholder jo bygginstruksene for tilvirkning av hele menneskekroppen. En teskje med DNA vil kunne tilsvare instrukser for ca. 350 ganger så mange mennesker som det lever i dag (ca. 7 milliarder). Informasjonen til disse vil knapt nok utgjøre en tynn hinne på den teskjeen.(21)
Om en vedlikeholdsmanual inneholdt sammenhengende, detaljerte instrukser for bygging, vedlikehold og reparasjon av en kompleks maskin, for bygging, vedlikehold og reparasjon -så vil ingen henføre det til tilfeldigheter. Likedan får de skriftlige instruksjoner i DNA tenkende mennesker, som ønsker å innse det, å bli overbevist om at det må være en intelligens inne i bildet. Om noe er skrevet, tenker en naturlig på hvem forfatteren er. Genomet er dessuten smartere enn en bok: Under de rette betingelser kan det kopiere, lese og reparere seg selv.
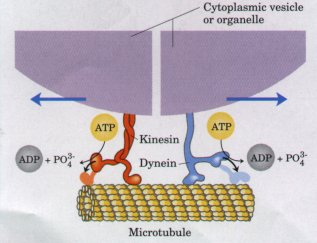 Nanomolekylære maskiner i bevegelse
Nanomolekylære maskiner i bevegelse
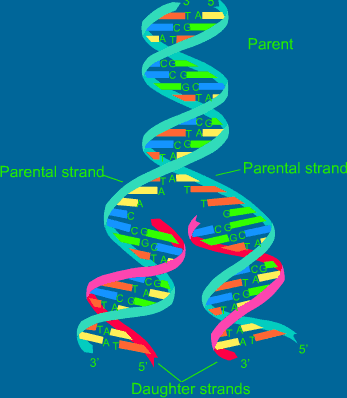
Replikasjon, lesning, av DNA foregår i cellekjernen. Om DNA hadde vært på størrelse med et jernbanespor, ville tilsvarende hastighet på enzymmaskinen som leser DNA ha vært over 80 km/t. Det skjer ved at noen molekylære maskiner går bortover DNA-tråden og splitter den i to. De bruker så hver tråd som mal for å lage en ny komplementær tråd. Enzymmaskinen leser ca. 100 basepar eller trinn sekundet. (23) I menneskecellen går flere hundre av disse replikeringsmaskinene til verks på ulike steder langs sporet av DNA. I løpet av 8 timer er hele menneskelig genom på ca. 3,2 milliarder tegn lest og kopiert.
Transkripsjon- avlesning av DNA
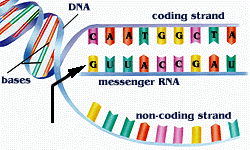 Bilde. Transkripsjon
Bilde. Transkripsjon
Selv om ikke DNA forlater cellekjernen, blir det likevel avlest og brukt utenfor denne. Det skjer ved at enzymmaskiner finner et sted langs DNA der et gen er slått på av kjemiske signaler, fra utenfor cellekjernen.Så benyttes RNA (ribonukleinsyre) til å lage en kopi av genet. RNA ligner, men er litt annerledes enn enkelttråd i DNA. Forskjellen ligger bl.a. i at T er erstattet med U (Uracil). Oppgaven til RNA er å hente ut informasjonen i DNA og overføre denne til ribosomene, cellens fabrikker, der informasjonen benyttes til å bygge proteiner. Dette er en kontinuerlig prosess som foregår 24/7. Enzymmaskinen som kopierer DNA fanger inn A, T, C og G-er, som flyter rundt. Så benyttes disse til å gjøre trinnene på den splittede DNA-stigen fullstendige. I løpet av menneskes levetid kopieres DNA ca 10 opphøyd i 16 ganer, og nøyaktigheten er upåklagelig. (28)
Oppdageren av DNA, Francis Crick, kom fram til at intelligente utenomjordiske vesener kunne ha sendt DNA til jorden for at det kunne bidra til at liv oppsto her. (26) Hvem som har skapt disse vesener har han ikke forklart. Den kjente filosofen A. Flew, som var ateist i over 50 år, gjorde helomvending da han hadde studert DNA skikkelig. Han mente at det ga rom for et guddommelig vesen. Hans begrunnelse var: "Jeg har alltid fulgt bevisene, uansett hvor de leder." Om en i en virksomhet oppdager et datarom der et høyst avansert program styrer alle arbeidsoppgavene, og i tillegg kontrollerer, bygger og reparerer maskiner, så ville en knapt konkludere med at dataprogrammet har laget seg selv.
 Men kompleksiteten blir enda mye større ved at en stor mengde gener kan være involvert i et vilkårlig antall egenskaper eller funksjoner. Tre oppdagelser spiller inn på hvorfor livet er mer enn bare DNA:
Men kompleksiteten blir enda mye større ved at en stor mengde gener kan være involvert i et vilkårlig antall egenskaper eller funksjoner. Tre oppdagelser spiller inn på hvorfor livet er mer enn bare DNA:
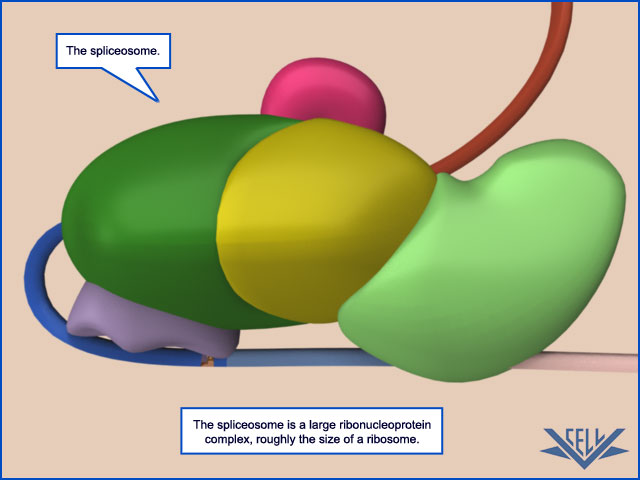
1. Alternativ spleising
 Det har vist seg at et enkelt gen kan gi anledning til dannelse av mange proteinvarianter, ved hjelp av såkalt gen-spleising. Det kan oppstå når et gens nukleotidsekvens er i ferd med å bli overført til messenger-RNAet. Det eksisterer en særlig gruppe på opp til 150 proteiner, sammen med fem RNA-molekyler, som vi kaller en spliceosom. Det dannes molekylære maskiner som skjærer RNAet opp i segmenter, som deretter re-kombineres i ulik orden. Noen ganger blir stykker fjernet og andre ganger tilføyd. Hver av stykkene har dermed en sekvens som avviker fra den opprinnelige. F.eks. finnes et gen i det indre øret hos høne og menneske, som gir 576 ulike former for proteiner. Det er også funnet et gen i bananfluen, som gir anledning til 38.016 ulike proteiner.
Det har vist seg at et enkelt gen kan gi anledning til dannelse av mange proteinvarianter, ved hjelp av såkalt gen-spleising. Det kan oppstå når et gens nukleotidsekvens er i ferd med å bli overført til messenger-RNAet. Det eksisterer en særlig gruppe på opp til 150 proteiner, sammen med fem RNA-molekyler, som vi kaller en spliceosom. Det dannes molekylære maskiner som skjærer RNAet opp i segmenter, som deretter re-kombineres i ulik orden. Noen ganger blir stykker fjernet og andre ganger tilføyd. Hver av stykkene har dermed en sekvens som avviker fra den opprinnelige. F.eks. finnes et gen i det indre øret hos høne og menneske, som gir 576 ulike former for proteiner. Det er også funnet et gen i bananfluen, som gir anledning til 38.016 ulike proteiner.
 Commoner peker på hvor ødeleggende denne oppdagelse er for troen på at den genetiske informasjon fra en original DNA-sekvens ender uendret i proteinets aminosyresekvens. Crick har uttalt at oppdagelsen av bare én type celle, hvori den genetiske informasjon videregis fra protein til nukleinsyre eller fra protein til protein, vil velte hele det intellektuelle grunnlaget for molekylærbiologien. Men det er nettopp hva som holder på å skje: Ny genetisk informasjon vil bli skapt i RNA ved en spleisingsprosess, via proteinene i et spliceosom.
Commoner peker på hvor ødeleggende denne oppdagelse er for troen på at den genetiske informasjon fra en original DNA-sekvens ender uendret i proteinets aminosyresekvens. Crick har uttalt at oppdagelsen av bare én type celle, hvori den genetiske informasjon videregis fra protein til nukleinsyre eller fra protein til protein, vil velte hele det intellektuelle grunnlaget for molekylærbiologien. Men det er nettopp hva som holder på å skje: Ny genetisk informasjon vil bli skapt i RNA ved en spleisingsprosess, via proteinene i et spliceosom.
Tidligere antok en at denne spleisingsprosessen var relativt sjeldent forekommende. Men nå har vi funnet at hyppigheten av alternative spleisinger stiger med organismenes kompleksitet. Det anslås nå at  opptil 75% av menneskets genom er omfattet av prosessen. Den informasjonsmengde som stammer fra alternativ spleising er enorm, så er det ikke så overraskende at det kan være store forskjeller mellom organismer med meget like gener.
opptil 75% av menneskets genom er omfattet av prosessen. Den informasjonsmengde som stammer fra alternativ spleising er enorm, så er det ikke så overraskende at det kan være store forskjeller mellom organismer med meget like gener.
2. Korrekturlesing
Den utrolig presise informasjonsoverføring fra DNA oppnås ikke bare på grunn av DNA. Det avhenger også i høy grad av den levende celle. I DNAets normale omgivelser i cellen, skjer replikasjon med omtrent en feil på 3 milliarder nukleotider. (Det menneskelige genom er ca. 3 milliarder nukleotider langt) Om det samme skjer i et reagensglass, øker feilprosenten drastisk til 1 til 100. Hvis så kjemikere tilsetter passende proteinenzymer, synker feilprosenten til omkring 1 til 10 millioner. At feilprosenten i cellen er enda mye lavere, avhenger av 'reparasjonsenzymer' som registrer og retter feil.
Prosessen med nuklein-syre replikasjon avhenger dermed av tilstedeværelsen av slike protein-enzymer, og ikke bare av DNAet. James Shapiro skriver: 'Det er forbausende å oppdage hvor grundig cellen beskytter seg mot den slags tilfeldige endringer, som skulle være kilde til den evolusjonære variasjon..' Levende celler er ikke tilfeldige ofre for kjemiens eller fysikkens krefter. De avsetter store ressurser for å undertrykke tilfeldig genetisk variasjon. De kan også fastsette nivået forandringer må foregå på, ved å justere aktiviteten av deres reparasjonssystemer. Som en parallell: en tar det gjerne for selvsagt at en tekst er korrekt, men ordlister og visning av avvik spiller en ikke ubetydelig rolle i det arbeidet. Det er eks. på intelligent aktivitet, evt. trykkleifer får være eks. på hva som skjer om 'tilfeldigheten råder'..

{kind=link}
Den største anstøtssten vi ramler inn i når vi prøver bygge bro mellom det ikke-levende og det levende, ligger i at alle levende celler er kontrollert av informasjon gjemt i DNA. Derfra transkriperes den over i RNA og deretter til protein. Det er et meget komplisert system, og hvert molekyl krever hver av de andre to sin tilstedeværelse. DNA kan ikke engang kopiere seg selv, uten hjelp fra RNA og proteiner. Det synes være en irredusibel symbiose her, som ikke forenklede opprinnelsesmodeller kan avspeile.
3. Proteinenes geometri
Når proteiner dannes, folder de seg sammen til en presis tredimensjonal geometrisk form. Og proteinets etterfølgende biokjemiske aktivitet er helt avhengig av denne formen. Vi vet nå at for at denne protein-foldingen skal foregå helt riktig, trengs 'anstands-proteiner' , som skal hjelpe dem oppføre seg korrekt, ellers blir de biokjemisk inaktive. Dessuten finnes nukleinsyre-fri 'prioner', involvert i f.eks. kugalskap. Forskning har vist at et prion trenger inn i et normalt hjerneprotein, og får det til å folde seg om igjen, slik at det får samme tredimensjonale struktur som prionet.
 Dette setter i gang en kjedereaksjon. Men både prionet og hjerneproteinet har samme aminosyresekvens. Dette tyder i høyeste grad på at den foldede struktur må være delvis uavhengig av aminosyresekvensen. For å bestemme informasjonsinnholdet i et protein, må en ta den tredimensjonale geometri som proteinet folder seg til, i betraktning. Det gjør det til et problem av svimlende proporsjoner..
Dette setter i gang en kjedereaksjon. Men både prionet og hjerneproteinet har samme aminosyresekvens. Dette tyder i høyeste grad på at den foldede struktur må være delvis uavhengig av aminosyresekvensen. For å bestemme informasjonsinnholdet i et protein, må en ta den tredimensjonale geometri som proteinet folder seg til, i betraktning. Det gjør det til et problem av svimlende proporsjoner..
I lys av at dette har vært kjent en tid, og det sentrale dogmet om at mutasjoner i molekyler utgjør hele forskjellen, -må en lure om det teorien fungerer mer som en religion enn en vitenskap. Uenighet, eller bare påpeking av et uharmonisk faktum, anses som kjetteri der kan lede til profesjonell utstøtelse. Det sentrale dogmet viser seg være 'for godt til å være sant'. Det ser ut til at det ligger noe mer i det å være menneske enn hva vi finner i genene.
Proteomik
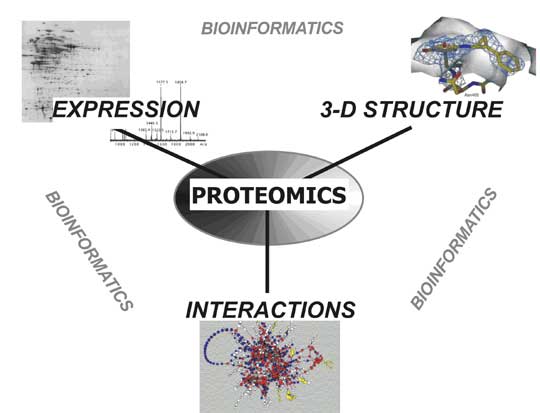
 Hierarkiet de ulike kompleksitetsnivåer inngår i, stopper ikke med oversettelse av den genetiske kode til proteiner. Proteiner kan også, i likhet med mRNA-molekylene, klippes og spleises på ulike måter. Det har ført til at det er oppstått en faglig disiplin: proteomik (eng: Proteomics) hvor proteomet er den totale mengde av proteiner og varianter av proteiner som finnes i en celle. Den er langt større enn genomets, og er en av de største utfordringer vitenskapen står overfor i dag.
Hierarkiet de ulike kompleksitetsnivåer inngår i, stopper ikke med oversettelse av den genetiske kode til proteiner. Proteiner kan også, i likhet med mRNA-molekylene, klippes og spleises på ulike måter. Det har ført til at det er oppstått en faglig disiplin: proteomik (eng: Proteomics) hvor proteomet er den totale mengde av proteiner og varianter av proteiner som finnes i en celle. Den er langt større enn genomets, og er en av de største utfordringer vitenskapen står overfor i dag.
Informasjonsbehandling i cellen
Jo mer cellen blir undersøkt, jo mer synes den ha til felles med et av de mest høyteknologiske produktene som menneskelig intelligens har frambragt: PCen. Matematikeren Douglas Hofstaedter skriver: 'Et naturlig og helt grunnleggende spørsmål en må stille nå som vi har lært disse utrolig intrikate innbyrdes avhengige deler program -og maskinvare å kjenne er: 'Hvordan er de overhodet kommet i stand fra starten av?' Spørsmålet er ikke blitt lettere av at denne koden oppfattes som ekstremt gammel. Werner Loewenstein, som har vunnet verdensberømmelse for sine oppdagelser i cellekommunikasjon og biologisk informasjonsoverføring sier: 'Dette genetiske leksikon går langt, langt tilbake i tid. Ikke en tøddel synes ha endret seg i over to milliarder år. Alle levende vesener på jorden, fra bakterier til mennesker, bruker den samme kode som består av 64 ord.
 Det er gjort forsøk på å benytte kjemiske bindinger som forklaringsmodelll. Men dette tilbakevises av Hubert Yockey, forfatter av 'Information Theory and Biology' sier rett ut: 'den gentiske tekst er ikke generert av kjemisk binding som finnes mellom molekylene.' 'Prebiotisk evolusjon' er anført av noen. Men Theodosius Dobzhansky sier: 'Prebiotisk evolusjon er -alene i sammensetningen av ord, selvmotsigende.' Ord som molekylærevolusjon forutsetter at vi har det til rådighet, som vi forsøker forklare: Den replikasjon som det alene gir mening å tale om at naturlig utvalg skulle ha en virkning på. James Clerk Maxvell hadde så tidlig som i 1873 observert at atomer besto av identiske partikler, hvis egenskaper ikke blir forandret ved naturlig seleksjon.
Det er gjort forsøk på å benytte kjemiske bindinger som forklaringsmodelll. Men dette tilbakevises av Hubert Yockey, forfatter av 'Information Theory and Biology' sier rett ut: 'den gentiske tekst er ikke generert av kjemisk binding som finnes mellom molekylene.' 'Prebiotisk evolusjon' er anført av noen. Men Theodosius Dobzhansky sier: 'Prebiotisk evolusjon er -alene i sammensetningen av ord, selvmotsigende.' Ord som molekylærevolusjon forutsetter at vi har det til rådighet, som vi forsøker forklare: Den replikasjon som det alene gir mening å tale om at naturlig utvalg skulle ha en virkning på. James Clerk Maxvell hadde så tidlig som i 1873 observert at atomer besto av identiske partikler, hvis egenskaper ikke blir forandret ved naturlig seleksjon.
Ikke desto mindre gjøres det stadig forsøk på å løse problemet med livets opprinnelse, utfra darwinistiske argumenter kun basert på tilfeldighet og tilbøyelighet. Det tvinger fram et matematisk bidrag for å analysere hva informasjon er.
Utvalg av stoff og bilder ved Asbjørn E. Lund